Visual Studio 프로젝트 옵션 중 Basic Runtime Checks가 있다.
이 옵션은 개발자가 저지르기 쉬운(하지만 찾기 어려운) 버그를 런타임 과정에서 찾아주는 기능이다.
프로젝트 설정의 C/C++ → Code Generation에서 설정이 가능하다.

그림 1과 같이 Defualt, /RTCs, /RTCu, RTC1 중 하나를 선택할 수 있다.
본 문서에서는 각 옵션 별 동작을 설명한다.
1. Stack Frames (/RTCs)
이 설정은 버퍼 오버플로우 발생 여부를 체크한다.
버퍼 오버플로우는 단순히 프로그램의 오동작을 일으킬 뿐만 아니라 버퍼 오버런 공격에 사용될 수도 있으므로 매우 유의해야 하지만
개발 과정에서 놓치기 쉽고, 디버깅도 쉽지 않은 버그 중 하나이다.
다음은 고의로 버퍼 오버플로우를 발생시킨 상황이다.

그림 2를 보면 pszMsg 배열에 할당된 메모리 주소는 0x3efcb0 ~ 0x3ecb2까지 3바이트인데 0x3ecb3도 00으로 설정이 된 걸 볼 수 있다. 이렇게 버퍼 오버플로우가 발생하면 이후 프로그램의 정상 동작을 보장하기 어렵게 된다.
'/RTCs' 옵션은 이러한 오버 플로우 발생을 방지한다.
'/RTCs'를 설정할 경우 지역변수 선언 시 스택에서 해당 변수 앞뒤의 메모리를 0xCC로 변경하고 이후 그 값이 변경되었는지를 검사한다.
만약 값이 변경이 되면 오버런 또는 언더런이 발생했다고 판단하고 예외를 발생시킨다.

그림 3을 보면 지역변수 pszMsg의 앞뒤로 메모리가 0xCC로 초기화되는 것을 확인할 수 있다.

그림 4에서 pszMsg에 할당된 메모리를 벗어난 0x10ffd67 영역이 0으로 변경되었고, 프로그램을 이를 감지하여 예외를 발생시킨다.
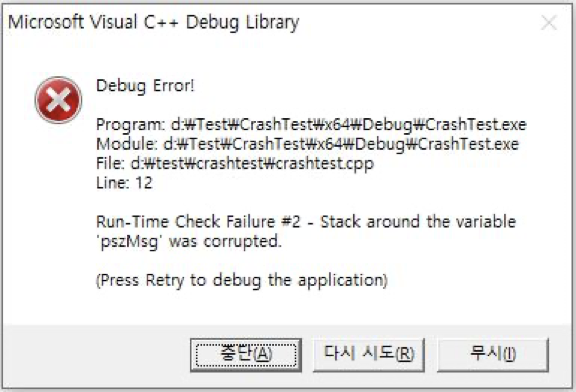
2. Uninitialized Variables (/RTCu)
이 설정은 초기화하지 않은 변수를 사용하고 있는지 체크한다.
/RTCu 설정을 하지 않으면 초기화되지 않은 변수를 사용하더라도 (운이 좋으면)프로그램은 동작하는데
설정을 할 경우에는 바로 예외를 발생시킨다.
3. Both (/RTC1, equiv. to /RTCsu)
이 설정은 /RTCs와 /RTCu 옵션을 모두 사용하는 설정이다.
4. Default
Default를 설정할 경우 모든 Runtime Check를 사용하지 않는다.
'IT기술 > Windows' 카테고리의 다른 글
| 마지막 부팅이 fast startup(빠른 부팅)으로 부팅 되었는지 확인하는 방법 (0) | 2020.02.23 |
|---|---|
| 왜 윈도우에서만 경로에 백슬래시를 사용할까 (0) | 2019.12.28 |
| Known DLL (알려진 DLL) (0) | 2019.12.14 |
| DLL 보안 - 안전하게 사용하기 (0) | 2019.12.08 |
| Windows에서 DLL 검색 순서 (0) | 2019.12.07 |

